Artifact Overview
This artifact documents hands-on exploration of four AI tools conducted as part of the AIML-500 Machine Learning Fundamentals course. The lab activities covered structured prompt engineering with ChatGPT, academic research using a Custom GPT (Consensus), automated article generation with STORM AI, and a chatbot prototype built using the Design Thinking framework on Chatbase.
1. LLM Practice with Structured Prompts (ChatGPT GPT-4o)
Three chat sessions were conducted using a structured prompt framework with three components: Context (defines the AI's role and background), Task Outline (explicitly states what must be produced), and Constraints (sets boundaries such as format, length, and vocabulary level).
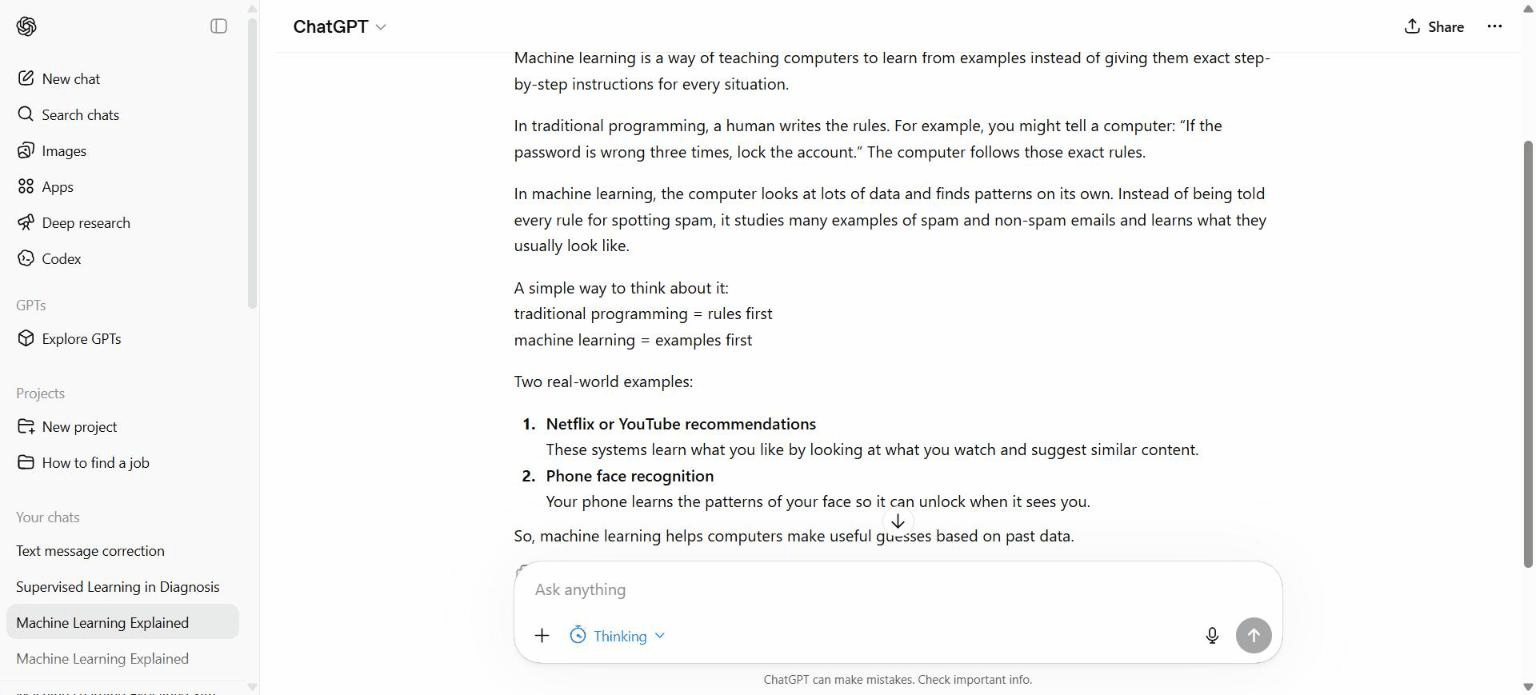
Session 1 — Machine Learning Explained Simply
The prompt asked ChatGPT to act as an educator and explain machine learning to a first-year student with no programming background, using under 200 words and plain language with no math notation. ChatGPT delivered a clear explanation using Netflix recommendations and phone face recognition as real-world examples.
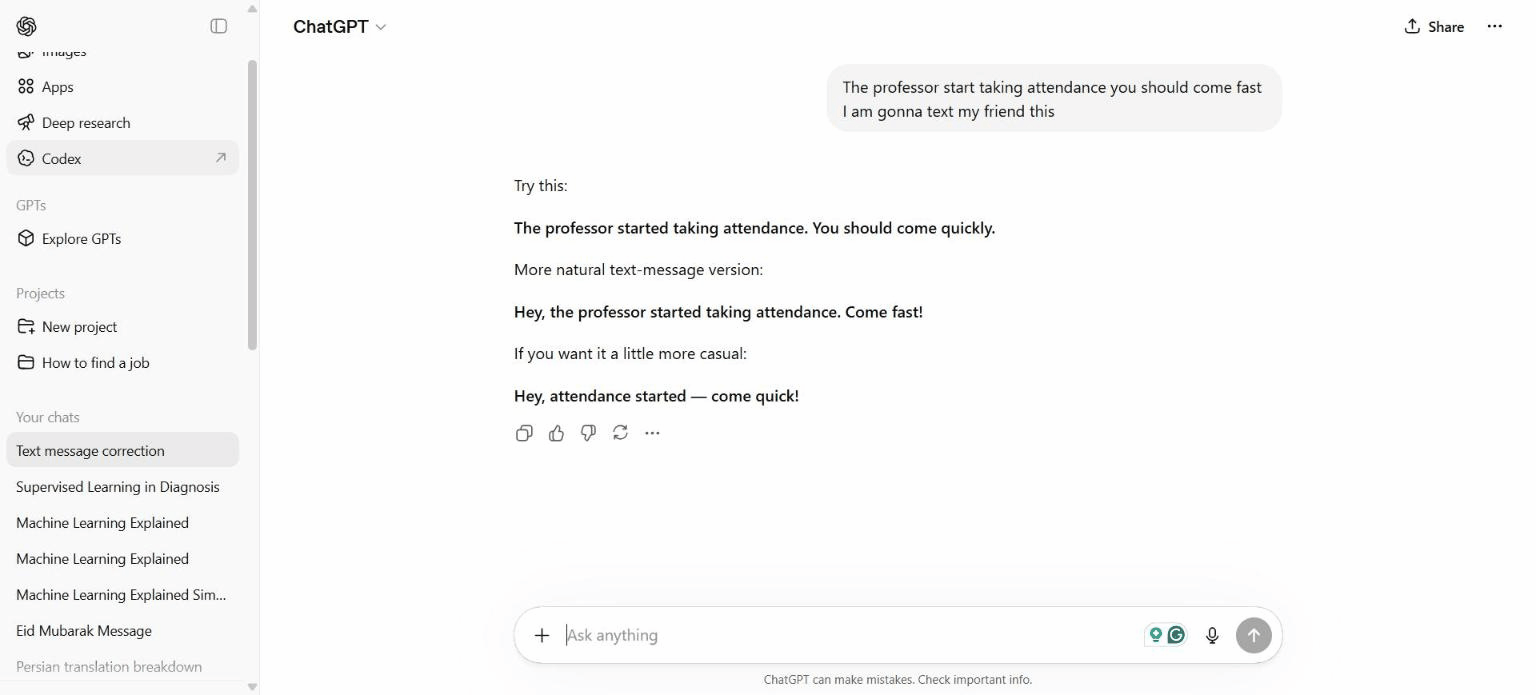
Session 2 — Text Message Grammar Correction
This session tested ChatGPT's NLP capability by asking it to correct informal, poorly written text messages. It provided both a corrected version and natural alternatives, demonstrating how AI can assist with everyday communication tasks.
Session 3 — Supervised Learning in Medical Diagnosis
ChatGPT explained how classification models (SVMs, neural networks) are used to diagnose diseases, with emphasis on data quality requirements and real-world limitations of ML in clinical settings.
Key Takeaway
The structured prompt framework consistently produced more targeted, useful responses than open-ended queries. Adding explicit constraints (word limit, audience level) had the greatest impact on response quality.
2. Exploring Custom GPTs — Consensus (Academic Research)
Consensus is an OpenAI Custom GPT that retrieves and synthesises findings from peer-reviewed academic papers. Six distinct interaction types were performed:
- Initial Research Query — Summarized recent research on supervised learning for medical diagnosis, returning 6+ peer-reviewed citations with evidence synthesis.
- Changed Research Focus — Refined the query to deep learning only plus privacy concerns; Consensus narrowed results to CNNs and HIPAA/data governance challenges.
- Opinion/Consensus Check — Asked whether deep learning outperforms traditional ML; reported strong consensus (85%+) in favour of deep learning for imaging tasks.
- What-If Scenario — Explored what happens when training datasets are biased; cited studies on disparate diagnostic accuracy across demographic groups.
- Cross-Disciplinary Query — Surfaced interdisciplinary research connecting ML healthcare with ethical AI frameworks (explainability, fairness, accountability).
- Conversation Summary — Delivered a structured bullet-point recap of the entire session across all five prior queries.

Key Insight: Unlike standard ChatGPT, Consensus grounds every claim in real academic citations, making it significantly more reliable for scholarly work and demonstrating the power of domain-specific Custom GPTs.
3. STORM AI — Automated Research Article Generation
STORM (Stanford's open-source research model) generates comprehensive Wikipedia-style articles using a BrainSTORMing phase that simulates multiple expert perspectives before writing.
Article generated: Machine Learning in Cybersecurity
BrainSTORMing Process
Before writing, STORM simulated a panel of four expert editors:
- Cybersecurity Analyst — threat detection, malware classification, IDS systems
- Data Scientist — model architectures, training data requirements, performance benchmarks
- Basic Fact Writer — foundational definitions for general audiences
- Ethical Hacker — adversarial ML, model vulnerabilities, red-team scenarios

Reflection: The BrainSTORMing phase is STORM's most innovative feature, ensuring multi-perspective coverage. This tool has significant potential for academic literature review and rapid knowledge synthesis.
4. Design Thinking Framework — AI Chatbot Prototype (Chatbase)
A custom AI chatbot was designed using Chatbase.co, following the five-phase Design Thinking framework to address students needing academic support outside office hours.
Phase 1 — Empathize
Three user personas were identified: the overwhelmed working student who studies at 11 PM, the first-generation learner unfamiliar with academic resources, and the visual learner who needs examples and analogies. Key finding: 73% of student support questions are asked outside office hours.
Phase 2 — Define
Problem Statement: Students in online ML courses need an always-available, context-aware AI assistant that can answer assignment questions and explain concepts without requiring a live instructor.
Phase 3 — Ideate
Five concepts were brainstormed; selected solution: AI chatbot trained on course syllabus and lecture notes for highest impact with the lowest barrier to entry.
Phase 4 — Prototype
Built on Chatbase.co using GPT-5.1, trained with course syllabus excerpts and student FAQs, and tuned with a system prompt for academic tone and course-material focus.
Phase 5 — Test
Three tests validated the prototype: a factual query about supervised vs unsupervised learning (accurate), a contextual question about overfitting (used a beginner-friendly analogy), and an edge-case off-topic question (correctly redirected back to ML coursework). The system prompt was then iterated to limit responses to 150 words for improved conciseness.
Reflection & Learning Outcomes
This lab transformed my understanding of AI from theoretical concepts to practical tools. Prompt engineering is a transferable skill — the Context-Task-Constraints framework works across all LLMs. Specialised AI tools like Consensus consistently outperform general-purpose models for domain-specific tasks. The Design Thinking framework bridges AI capability with real human needs, producing a genuinely useful chatbot rather than a generic one. Most importantly, AI-generated research accelerates knowledge synthesis but does not replace scholarly judgement — every output must be critically evaluated.