Artifact Overview
This artifact documents a collaborative group presentation on "Machine Learning & Deep Learning Foundation," delivered during the Friday residency session of Workshop 2. Our five-member team researched, designed, and presented a comprehensive 16-slide comparison of Machine Learning and Deep Learning to classmates and the instructor.
I selected this artifact because it demonstrates a fundamentally different skill set from Artifact 1. Where the AI Lab showcased individual tool exploration, this presentation highlights technical depth in core ML/DL concepts, collaborative teamwork, presentation design, and the ability to communicate complex material to a mixed audience.
The Team

Section 1: Introduction — The Big Picture
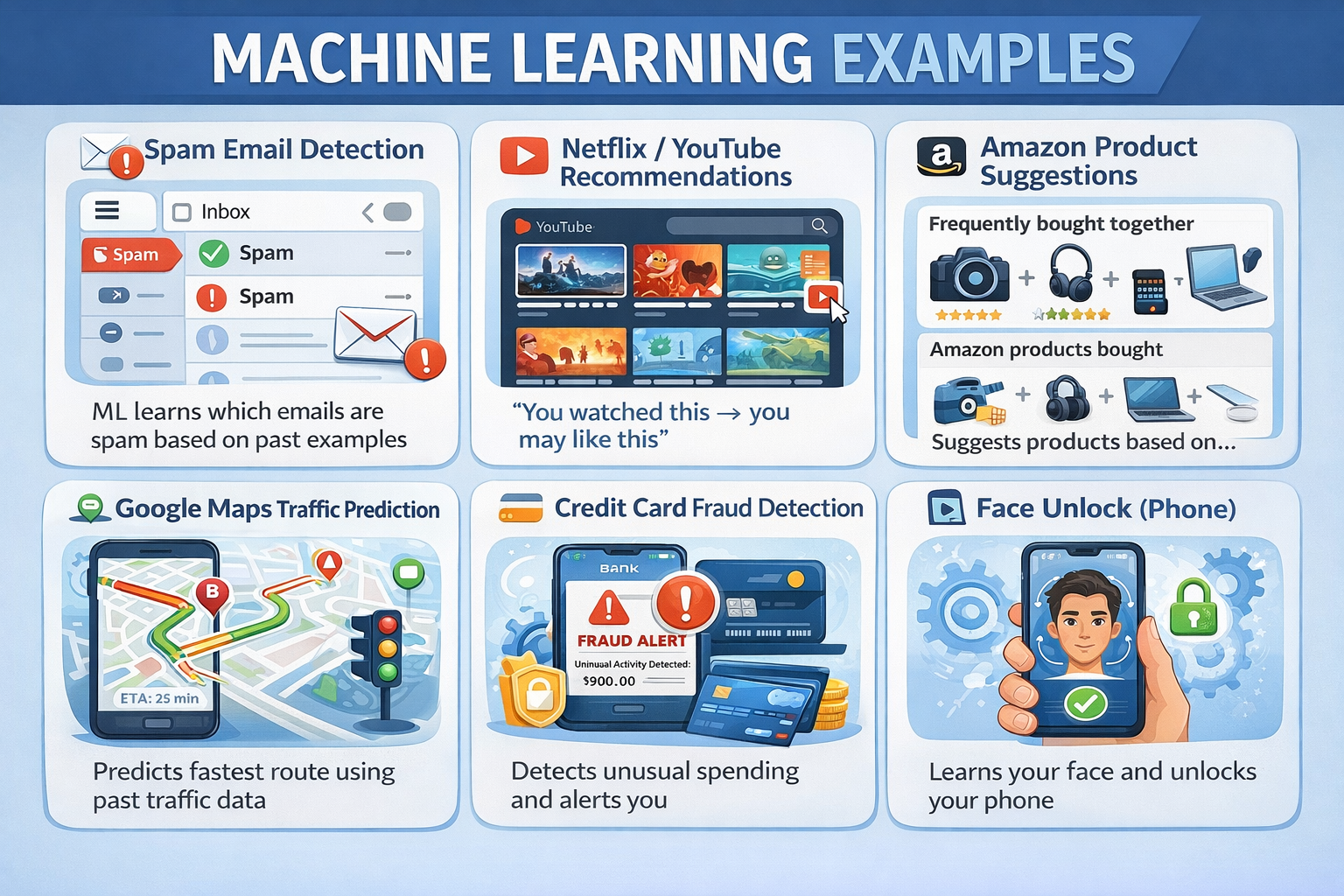
The presentation opened with two relatable examples — spam filtering in email and tumor detection in MRI scans — to ground the audience before introducing terminology. The key analogy: Machine Learning is like a structured student who needs clear instructions, while Deep Learning is like an abstract thinker who learns patterns on its own.

Section 2: Machine Learning — The Structured Student
This section explained the ML pipeline: input data, human-defined feature extraction, algorithm processing (Decision Trees, Logistic Regression), and output predictions. ML requires humans to tell the system what to look for. It is fast, works well with structured tabular data, and produces explainable results.
Section 3: Deep Learning — The Abstract Thinker
Deep Learning was explained through artificial neural networks with input, hidden, and output layers. The key distinction: DL learns features automatically. We walked through a medical imaging example where early layers detect edges, deeper layers detect shapes, and final layers identify complex patterns like tumors. Key architectures covered: CNNs for images and RNNs for text/speech.


Section 4: Head-to-Head Comparison
The comparison distilled differences into three dimensions: feature extraction (manual vs. automatic), data/compute requirements (small datasets on a laptop vs. massive datasets on GPUs), and transparency (explainable vs. black box).

Section 5: When to Use Each Approach
The conclusion provided a clear decision framework: use ML when data is structured, the problem is well-defined, and you need explainability (spam detection, sales forecasting). Use DL when data is complex and unstructured — images, audio, text — and patterns are too difficult for humans to define (medical imaging, speech recognition). Key takeaway: choose the right tool for the problem, not the most advanced one.

Reflection
This artifact showcases a completely different dimension of my capabilities compared to Artifact 1. While the AI Lab demonstrated individual tool exploration, this presentation required deep understanding of core ML and DL concepts and the ability to communicate them clearly to an audience. The most important lesson: the choice between ML and DL is not about which is "better" — it is about which is appropriate for the problem. A simple Decision Tree that is fast and explainable can be far more valuable than a deep neural network that requires massive compute and cannot explain its decisions.